Hybrid Multi-Agent Factuality Framework
Our hybrid system combines a multi-agent orchestration built with Google’s Agent Development Kit (ADK) and a set of factuality factor machine learning models trained on LIAR-PLUS. The agents and models collaborate to evaluate news articles along four factuality dimensions and produce an interpretable, overall credibility assessment.
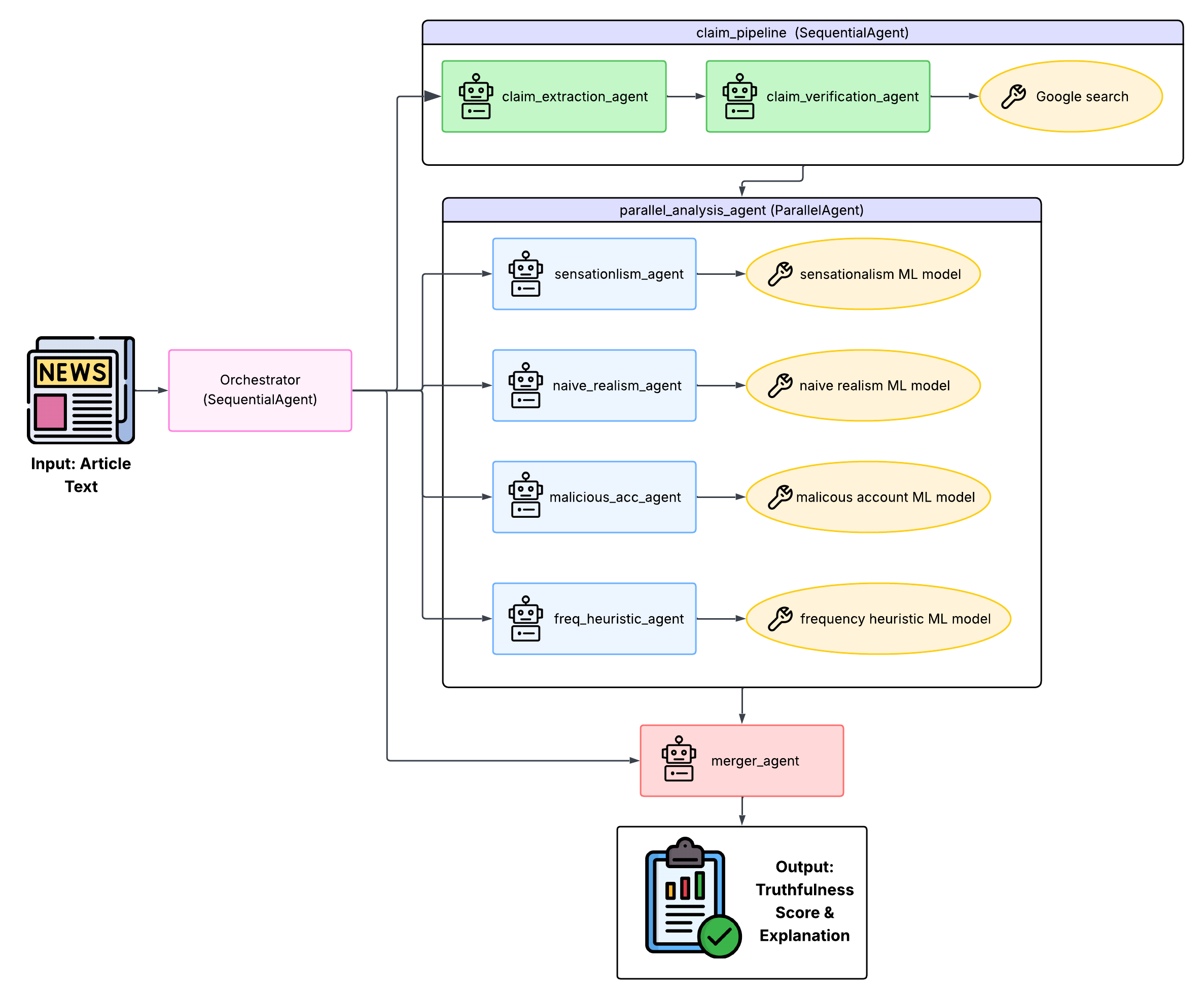
System architecture overview
We decomposed the factuality evaluation process into three layers:
- Claim extraction and verification – identify and verify atomic factual claims in an article.
- Parallel factuality analysis – four specialized LLM agents independently score different factuality factors in parallel.
- Sequential score aggregation – a merger agent combines factor-level outputs into an overall truthfulness assessment.
Layer 1 Claim extraction & verification
The claim extraction agent decomposes an article into testable factual claims that satisfy three constraints:
- Factual rather than purely opinion or rhetoric.
- Testable against external sources.
- Self-contained and unambiguous.
The agent outputs a structured list of claims that downstream components treat as the unit of verification.
For each extracted claim, a verification agent calls a google_search tool within ADK to retrieve relevant evidence. For every claim, the agent:
- Constructs a targeted search query.
- Calls the search tool to retrieve candidate sources.
- Assesses the credibility and agreement of retrieved information.
- Assigns a verification status and confidence score.
This follows a retrieval-augmented reasoning pattern: instead of relying solely on an LLM’s internal knowledge, it explicitly grounds its judgments in up-to-date external evidence, reducing hallucinations.
Layer 2 Parallel factuality factor agents
The core analysis layer consists of four independent LlmAgent instances, each responsible for one factuality factor:
All four agents are grouped under a ParallelAgent so that they can execute concurrently. Importantly, agents do not share intermediate analysis, preventing cross-contamination between factors.
Tools: ML models as callable functions
get_frequency_heuristic_prediction(text)) to get a score and confidence.
Prompts tell agents to treat model outputs as informative but not ground truth. If an agent disagrees with the model score, it has to explain why. The hybrid design lets us:
- Use supervised models for pattern-based grounding learned from thousands of labeled statements.
- Lean on LLMs for contextual nuance and interpretability at the article level.
Layer 3 Sequential orchestration & aggregation
A SequentialAgent acts as the root controller and runs the full pipeline:
- Invoke claim extraction and verification.
- Launch parallel factuality factor evaluations.
- Pass all factor outputs to the merger agent.
The merger agent then synthesizes the four factor-level outputs into an overall truthfulness score, produces a final explanation that highlights which factors mattered most, and enforces a strict JSON schema for all agent outputs.
Agent-to-Agent (A2A) Deployment
To make the system easier to integrate into other applications, we deploy each
specialized factuality factor agent as an Agent-to-Agent (A2A) service using
ADK’s to_a2a functionality.
- Each agent can run as a standalone service on its own port, ready to be integrated into future pipelines.
- Execution environments are isolated, guaranteeing that prompts, tool calls, and outputs remain cleanly separated between factors.
Methodological trade-offs
Our design has several trade-offs:
- Pros: interpretable factor scores, modular agents, and explicit grounding in supervised models and external evidence.
- Cons: increased computational overheadfrom multi-agent orchestration and multi-iteration reasoning.